Index와 Partition
Index와 Partition
Q0. SQL의 종류는 무엇이 있을까?
보기
-
DDL (Data Definition Language)
- 스키마를 관리하는 작업을 수행하는 명령어
- CREATE, ALTER, DROP등 데이터베이스 및 테이블을 관리하는 쿼리들
- 함수, 프로시저 등의 명령어들도 DDL에 해당함
-
DCL (Data Control Language)
- 데이터 접근을 제어하는 명령어
- GRANT를 이용하여 데이터 베이스의 권한을 제어하는 쿼리 (←→ REVOKE)
- COMMIT, ROLLBACK 등의 명령어가 DCL에 해당함
-
DML (Data Manipulation Language)
- 데이터를 조작하는 명령어
- SELECT, INSERT, UPDATE, DELETE 등의 쿼리들
Q1. Index의 종류는 무엇이 있을까?
보기
- 클러스터드(Crustered) 인덱스
- 프라이머리 키에서만 사용하는 인덱스 (테이블 당 1개만 생성 가능)
- 프라이머리 키 기준으로 물리적으로 정렬해서 저장한다.
- INSERT, UPDATE 등의 DML에 대해 데이터 위치를 수정해야하므로 성능이 느리다.
- 수정이 빈번한 테이블은 해당 인덱스를 사용하지 않는 것이 유리할 수 있다.
- 넌클러스터드(Non Crustered) 인덱스
- 테이블에 여러 개의 인덱스 생성 가능
- 하지만 테이블당 5개를 넘지 않는게 좋다고 함
- 별도의 index page를 생성하여 인덱스 저장
- index page에 row id를 참조하여 데이터에 접근 한다.
- unique 제약조건은 자동으로 unique 인덱스를 생성한다.
- 테이블에 여러 개의 인덱스 생성 가능
- 결합 인덱스
- 두 칼럼 이상 결합하여 지정된 인덱스
참고) Index를 사용할 때 주의해야하는 점
보기
- 전체 데이터에 15% 정도의 ROW를 조회하는 경우에 생성하는 것이 좋다.
- 테이블에 데이터가 적으면 Full Table Scan 하는 것이 더 좋다.
- Index에 의한 오버헤드보다 속도가 좋다.
- Index는 단일 I/O이기 때문에 (Random Access)
- 인덱스는 유일한 값이나 범위가 넓은 칼럼에 지정하는 것이 좋다.
- NULL이 아닌 칼럼에 지정하는 것이 좋음
- 결합 인덱스는 칼럼 순서가 굉장히 중요하다.
- 보통 자주 사용하는 칼럼을 선행으로 지정
- 한 테이블에 인덱스는 너무 많이 만들지 않는 것이 좋다.
- 인덱스 갱신에 대한 오버헤드가 있기 때문
- 한 테이블에 5개를 넘지 않는 것이 좋다고 한다.
- 추가, 수정, 삭제가 빈번한 테이블에는 인덱스를 만들지 않는 것이 좋다.
- 인덱스는 DML 작업에 성능이 좋지 않기 때문
- 검색(SELECT)가 많은 테이블에서 사용하는 것이 좋다.
- 인덱스가 있는 경우 쿼리가 인덱스를 충분히 활용할 수 있도록 작성하도록 하자.
- good) WHERE user_id LIKE 'NT%'
bad) WHERE user_id LIKE '%NT%'
LIKE 연산자에서 %를 사용하는 경우 앞에 %를 사용하면 인덱스를 사용하지 못한다. - good) WHERE year = string_to_date('2019')
bad) WHERE date_to_string(year) = '2019'
조회하는 칼럼을 가공하면 인덱스를 활용하지 못한다. 조건을 가공해서 비교하도록 하자.
- good) WHERE user_id LIKE 'NT%'
Q2. 파티션은 무엇이고 왜 사용하는가?
보기
- 파티션
- 하나의 테이블을 여러 테이블로 나누어 저장할 수 있도록 해주는 방법이다.
- 사용자는 하나의 테이블로 사용하지만 DBMS는 여러 테이블로 나눠 저장한다.
Q. 인덱스 성능이 저하되는 경우 파티션을 통해 개선할 수 있다. 어떻게?
사용 이유 : 한 테이블에 데이터가 너무 많아지면 성능이 저하된다.
- 잘 사용하지 않는 데이터로 인해 테이블 성능이 저하된다.
- 한 테이블에서 자주 사용되는 데이터는 일부이다. (20~30%) ex) 휴면 고객
- 히스토리성 테이블 같은 경우 과거 데이터는 불 필요해진다.
- 데이터가 많아지면 인덱스 크기가 커져 성능이 저하된다.
- 인덱스 갱신 작업의 오버헤드가 커진다.
- 인덱스 크기가 메모리 크기 이상으로 커지면 성능이 크게 저하된다.
위와 같은 경우에 파티션을 이용하여 테이블을 분할 저장하고 자주 사용되는 데이터만 모으거나 인덱스 크기를 줄인다.
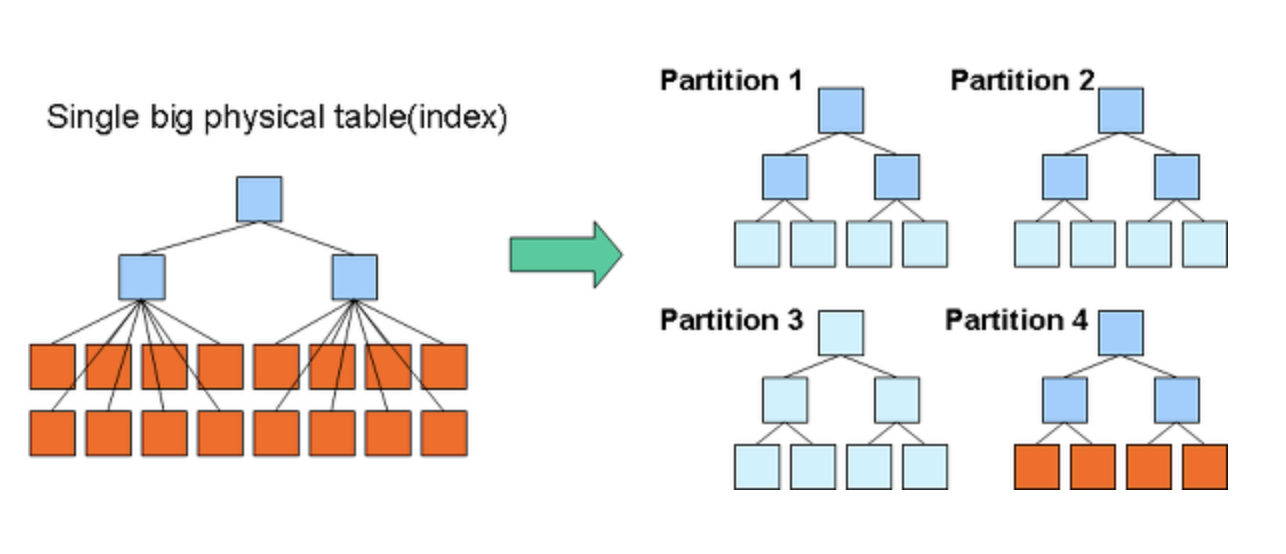
파티션을 통해 히스토리성 데이터는 날짜별로 분할 저장할 수도 있고 자주 사용하는 데이터만 모아 테이블과 인덱스를 재구축하여 조회, 갱신 성능을 향상 시킬 수도 있다.
Q3. 파티션 된 테이블을 사용할 때 주의할 점이 있을까?
보기
- 파티션을 결정할 수 있는 조건을 WHERE절에 사용하도록 한다.
- WHERE절에서 특정 파티션을 결정할 수 있는 조건이 없는 경우 모든 파티션을 조회해야 한다.
- 각 파티션의 인덱스를 활용할 수 있는 조건을 WHERE절에 사용하도록 한다.
- 이것은 보통의 인덱스 활용 목적과 동일 (조회 성능을 향상 시키기 위함)
Q. 둘 중 어떤 것이 더 성능에 영향을 크게 미칠까?
A. 일반적으론 인덱스가 더 성능에 크게 영향을 미친다.
- 파티션 결정(O) + 인덱스(X)
조건에 의해 파티션은 결정했지만 인덱스가 없어서 Partition(Tabel) Full Scan을 수행한다. - 파티션 결정(X) + 인덱스(O)
모든 파티션에 대해 Index Range Scan을 수행한다.
- 파티션에 존재하는 데이터 크기에 따라 다르겠지만 보통 파티션을 하는 경우 데이터가 많기 때문이므로 Index Range Scan이 Full Scan보다 성능이 훨씬 좋다.
- 그러나 파티션은 많아야 몇 개 안되기 때문에 첫번째 경우보다는 두번째 경우가 성능이 더 좋다.
- 물론 두가지 모두 활용할 수 있도록 조건을 활용하는 것이 가장 좋다.
참고
파티션 프루닝 (Partition Pruning)
조회 조건에 의한 실행 계획 (옵티마이저)에서 특정 파티션은 조회하지 않아도 된다고 판단하여 해당 파티션을 배제하는 것을 파티션 프루닝 (Partition Pruning)이라고 한다.