RDBMS 일반
비교
Q0. Delete와 Truncate와 Drop의 차이는?
보기
- delete
- 데이터만 삭제하고 저장 공간은 유지된다.
- commit과 rollback이 가능하다.
- 전체 또는 일부 삭제가 가능하다.
- 트랜잭션 처리를 위한 오버 헤드로 속도가 느리다.
- DML이다.
- truncate
- 데이터를 모두 제거하고 저장 공간을 반납한다.
- commit, rollback이 불가능하다. (자동 commit)
- 오버 헤드가 없어서 빠르다.
- DDL이다.
- 테이블이 남아있다.
- drop
- 데이터와 테이블을 제거하고 저장 공간을 반납한다.
- commit, rollback이 불가능하다.
- 빠르다.
- DDL이다.
- 테이블이 제거된다.
트랜잭션 (Transaction)
Q1. 트랜잭션의 특징은?
보기
ACID
- 원자성(Atomicity) : 트랜잭션은 모두 반영되거나 반영되지 않아야 한다.
- 일관성(Consistency) : 트랜잭션의 처리 결과가 항상 일관성이 있어야한다.
- 독립성(Isolation) : 어느 하나의 트랜잭션이라도 다른 트랜잭션에 끼어들 수 없다.
- 지속성(Durability) : 트랜잭션이 성공한 경우 결과는 영구적으로 반영되어야 한다.
Q2. Isolation Level과 특징
(MySQL 기준으로 설명)
보기
-
Read Uncommited
- Update 후 Commit되지 않은 데이터도 읽을 수 있음
- Dirty Read가 발생할 수 있다.
- Dirty Read : 트랜잭션이 완료되지 않았는데 다른 트랜잭션에서 읽게 되는 현상
-
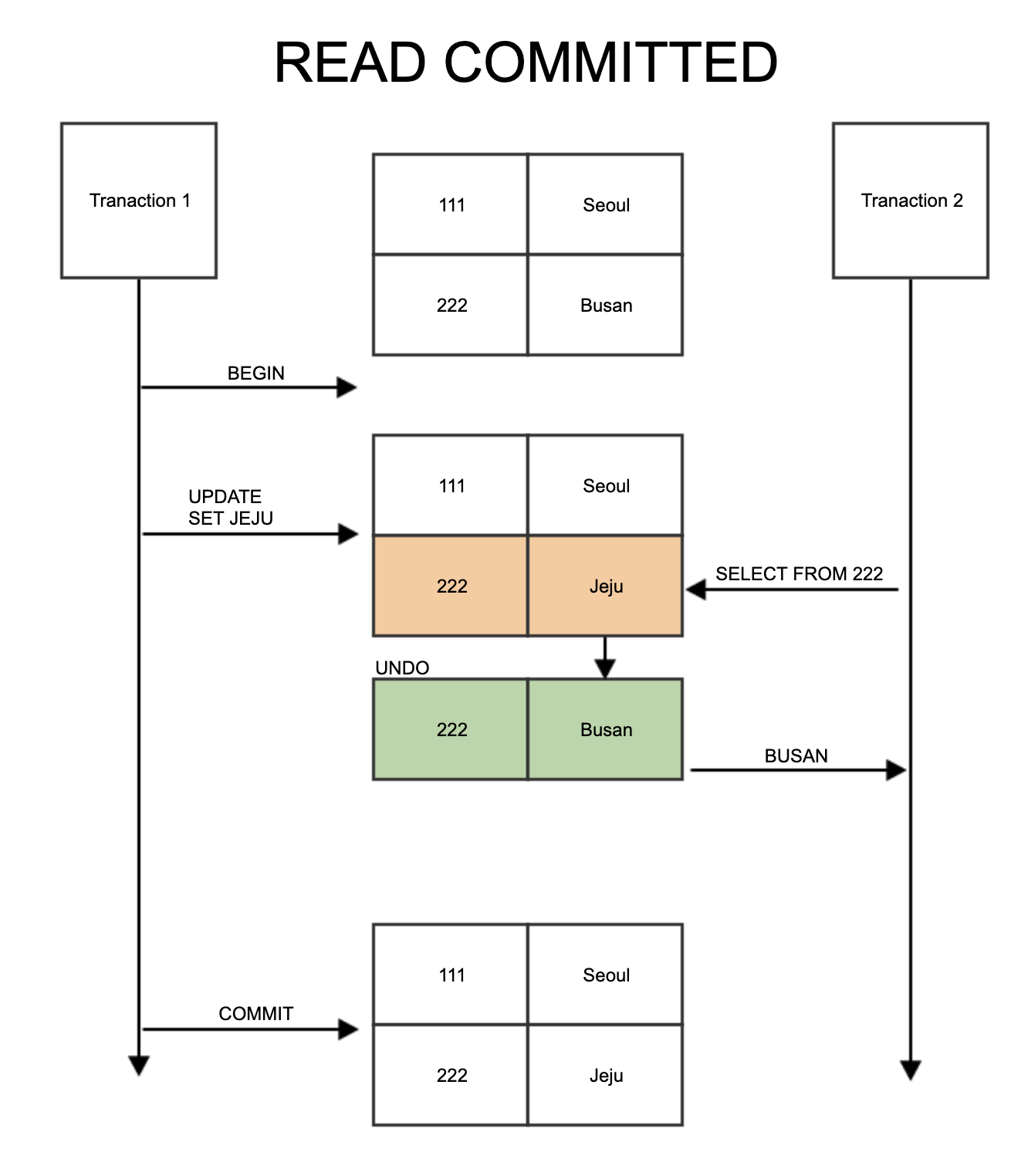
Read Commited
- Update 후 Commit된 데이터만 읽을 수 있음
- 실제 데이터를 조회하는 것이 아니라 Undo 영역의 데이터를 조회한다.
- Dirty Read는 발생하지 않는다. 하지만 Unrepeatable Read가 발생한다.
- Unrepeatable Read : 한 트랜잭션에서 연속해서 SELECT를 했을 때 다른 값을 읽는 현상
- 첫번째 SELECT에서는 Undo 영역을, 두번째는 Record를 읽는 경우 값이 다름
-
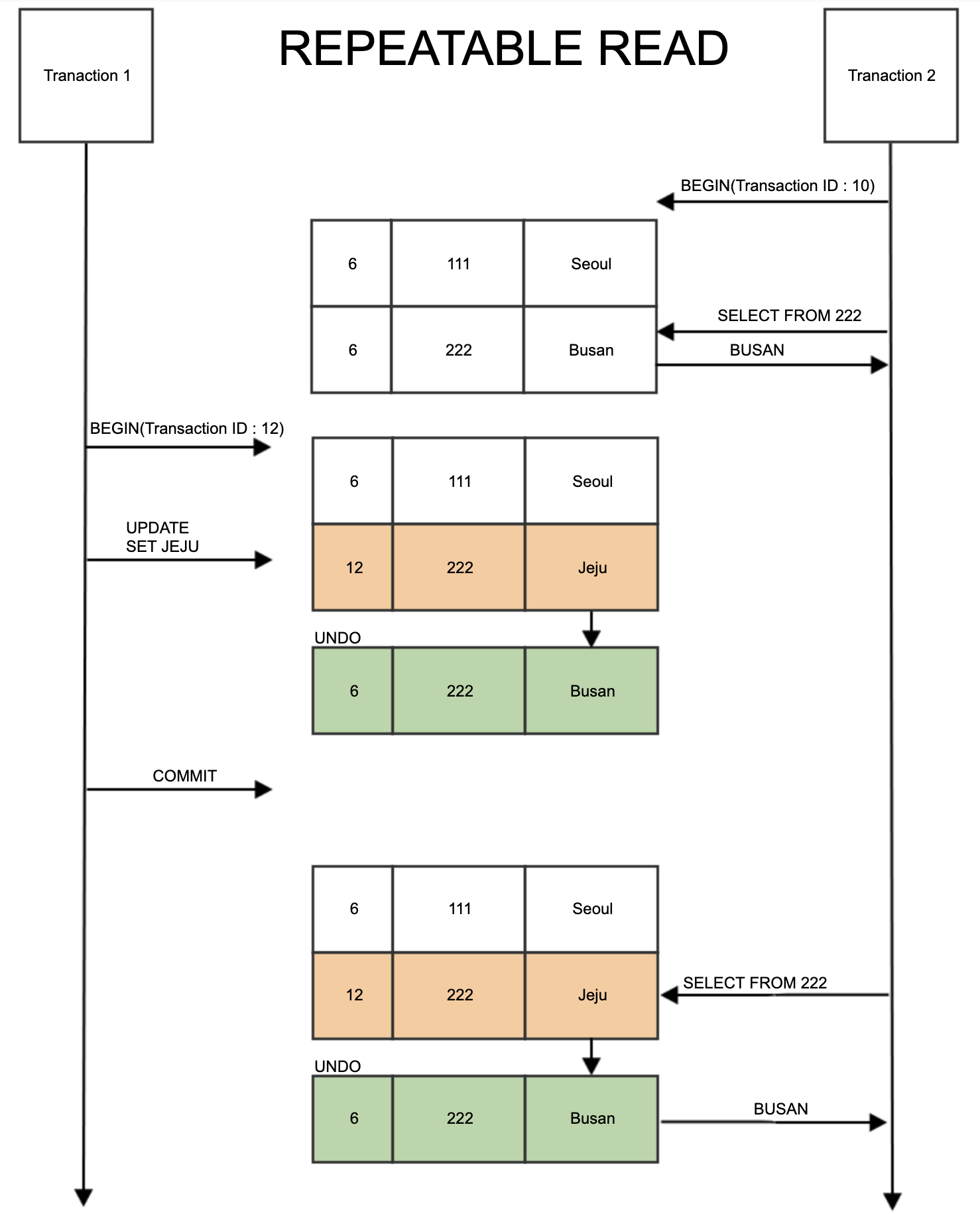
Repeatable Read
- Unrepeatable Read를 해결한 Isolation Level
- (MySQL의 경우) 매 트랜잭션 ID를 부여하고 자신보다 낮은 ID의 트랜잭션 데이터만 볼 수 있도록 해서 해결했다. (즉 나보다 먼저 끝난 트랜잭션 결과만 볼 수 있음)
- Undo 영역에 데이터를 백업해두고 나보다 이전에 수행된 트랜잭션은 해당 Undo 영역을 보도록 한다. (Shared Lock - SELECT는 가능하도록 하는 Lock)
- Phantom Read가 발생할 수 있음
- Phantom Read : 다른 트랜잭션에 의해 데이터가 보였다 안보였다 하는 현상
- Unrepeatable Read를 해결한 Isolation Level
-
Serializable
- 가장 엄격한 격리수준
- 동시성 문제는 해결했지만 동시처리 성능이 가장 떨어진다.
- Phantom Read는 발생하지 않지만 성능이 떨어져 거의 사용하지 않는다.
Shared Lock과 Exclusive Lock
MySQL에서는 두가지 lock을 사용한다.
Shared Lock(공유 Lock)은 Select만 하는 다른 트랜잭션을 위해 Undo 영역에 현재 수정하는 데이터를
백업해두고 해당 데이터를 읽을 수 있도록 해주는 Lock이다.Exclusive Lock(배타적 Lock)은 다른 트랜잭션이 Select도 할 수 없도록 하는 Lock이다.
정규화
Q3. 정규화를 하는 이유가 무엇인가?
보기
데이터의 중복을 최소화하고 삽입, 삭제, 갱신 작업에서 발생 할 수 있는 이상 현상을 방지하기 위해 정규화를 진행한다.
Q4. 역정규화를 하는 이유가 무엇인가?
보기
정규화를 진행할수록 여러 테이블로 나눠지기 때문에 데이터 조회 시 Join 해야 하는 테이블이 많아진다. Join에 들어가는 비용이 커지기 때문에 역정규화를 한다.
용어
Q5. 샤딩(Sharding)과 레플리카(replica)에 대해 설명해보세요.
보기
샤딩(Sharding)
- 성능과 가용성을 위해 데이터를 분산하여 저장하는 것
레플리카(replica)
- 가용성을 위해 데이터를 복제하여 분산 저장하는 것
둘의 차이점
샤딩은 서로 다른 데이터를 key 기반으로 분산 저장하는 것이고 레플리카는 같은 데이터를 복제하여 백업 데이터를 분산 저장하는 것
DB를 master-slave 구조로 하여 READ는 slave에서, 추가, 수정, 삭제는 master에서 하도록 하는 것도 일종의 레플리카로 볼 수 있다.
RDBMS 관점에서 샤딩과 레플리카
파티셔닝
파티셔닝은 크게 세가지로 나뉜다.
- 수직적 파티셔닝
- 테이블의 칼럼을 나눠 저장한다. (= 정규화)
- 수평적 파티셔닝
- 테이블의 Row를 나눠 저장한다. (= DBMS의 파티셔닝 기능)
- 범위 기반 파티셔닝
- 테이블을 기능별로 나눠 저장한다.
수직적 파티셔닝 = 정규화
수평적 파티셔닝 = 샤딩, DBMS의 파티셔닝 기능
레플리카 = DB master-slave 구조