Join
Join
Q0. 테이블을 결합하는 방식에는 어떤 것들이 있나요?
보기
- Join
- Scala Subquery
Q1. Join의 종류는 어떤 것들이 있나요?
보기
- Inner Join
- 두 테이블을 On 절의 조건으로 결합하여 결과를 도출하는 Join
- 둘 중 한쪽에 데이터가 없는 경우 결과 도출을 하지 않음
- Outer Join
- 결합하고자 하는 테이블에 On절 조건에 맞는 데이터가 없더라도 결과를 도출하는 Join
- Left Outer Join과 Right Outer Join이 있다.
- Left 조인
- 왼쪽 테이블 데이터를 기준으로 오른쪽 테이블을 Outer Join함
- 오른쪽 테이블에 데이터가 없는 경우 오른쪽 테이블의 각 칼럼을 NULL로 채움
- Right 조인
- 오른쪽 테이블을 기준으로 왼쪽 테이블을 Outer Join함
- 왼쪽 테이블에 데이터가 없는 경우 왼쪽 테이블의 각 칼럼을 NULL로 채움
- Full Outer Join
- Left와 Right Outer Join을 동시에 수행
- 두 테이블 중 한쪽에 데이터가 없는 경우 NULL로 채워 결과를 도출
- Cross Join
- 두 테이블의 곱 집합을 반환
- Cartesian Product (카디션 곱)이라고도 한다.
- 두 테이블의 각 row의 곱만큼의 데이터가 생성된다.
- Self Join
- 자기 자신을 Join
Q2. Join의 방식에는 은 어떤 것들이 있는가?
보기
- Nested Loop Join
- Merge (Sort Merge) Join
- Hash Join
상세한 구조는 DBMS마다 조금씩 다를 수 있으므로 일반적으로 적용되는 경우에 대해서만 설명
Q3. Nested Loop Join에 대해 설명하세요. (성능 관점에서)
(처리 과정과 특징)
참고
Driving Table : Join 수행 시 기준이 되는 테이블(선행 테이블), Outer Table이라고도 함, Join 대상 테이블(후행 테이블)은 Inner Table이라고 함
Nested Loop Join
가장 일반적인(많이 쓰이는) 조인 방식이다.
먼저 드라이빙 테이블로부터 데이터를 조회하고 해당 데이터와 Join되는 데이터들을 가져와 순차적으로 결합하는 방식이다.
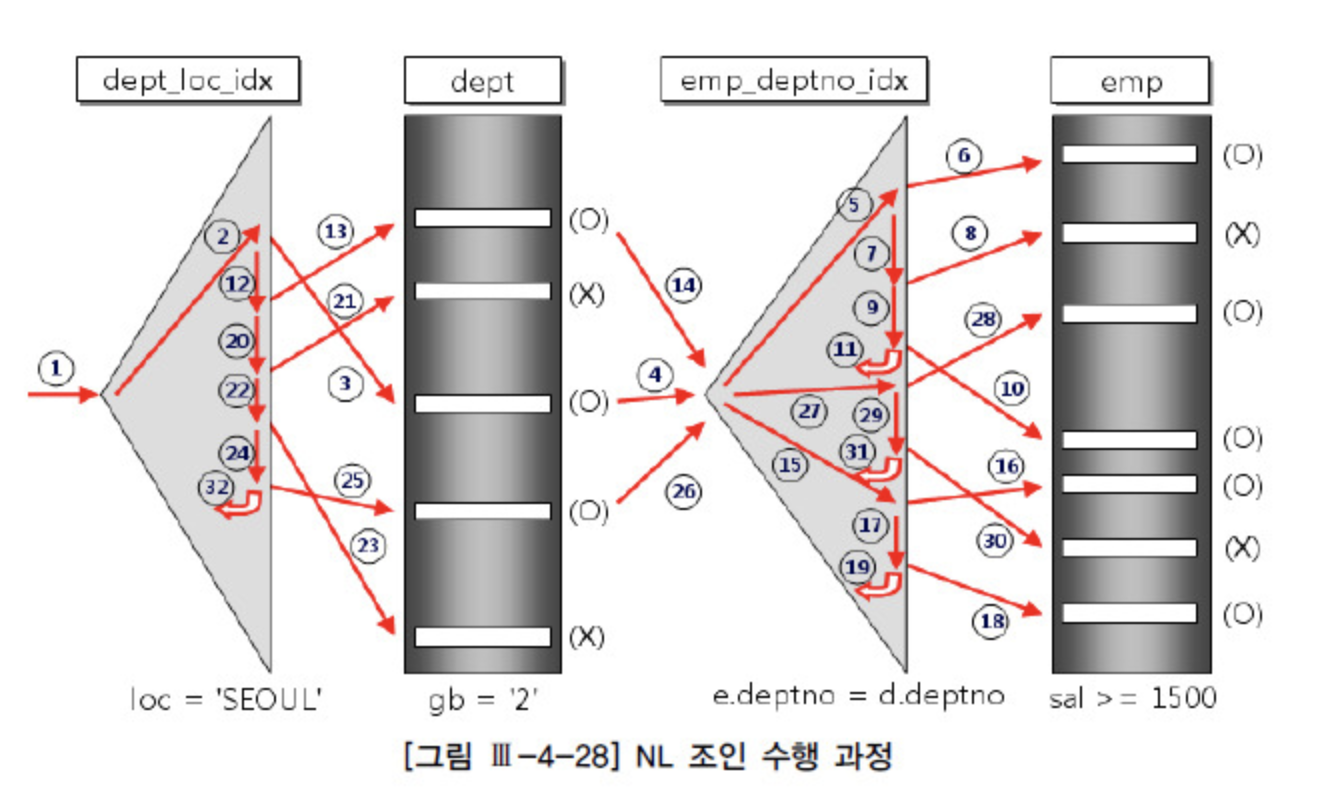
처리 과정
- 먼저 드라이빙 테이블에 대해서 필터링 후 드라이빙 테이블 데이터를 조회한다.
- 결합 조건에 의해 후행 테이블과 Join을 수행, Join은 각 row를 순차적으로 수행한다.
- 최종 결과를 도출하기 위해 나머지 필터링 수행
성능 상의 특징
- 성능은 드라이빙 테이블에서 1차 필터링 했을 때의 데이터 양에 의해 결정된다.
선행 테이블 데이터가 적으면 조인 수행 시 후행 테이블 접근 시 Random Access가 발생한다.
따라서 후행 테이블 접근 횟수에 따라 성능이 좌우된다. 선행 테이블에서 row수를 줄여 주는 게 중요하다.
그래서 두 테이블을 Nested Loop Join으로 조인하는 경우 데이터가 적은 쪽을 드라이빙 테이블로 선정하는 것이 좋다. - 후행 테이블을 위한 Index를 추가하자.
후행 테이블 접근 시 Random Access가 발생하므로 Index를 생성해서 Disk I/O를 최소화하는 것이 성능에 좋다.
On절 조건에 의해 Join 수행시 Index만으로 데이터를 찾아갈 수 있도록 하기 위함이다.
Q4. Merge (Sort Merge) Join에 대해 설명하세요. (성능 관점에서)
Merge Join
조인하는 두 테이블을 각각 조회(필터링)하고 결합 조건 칼럼을 기준으로 정렬 한 후 결과를 차례로 Merge하면서 결합하는 방식. 조인 조건이 Equal(=)이 아닌 경우에 자주 사용된다고 한다.
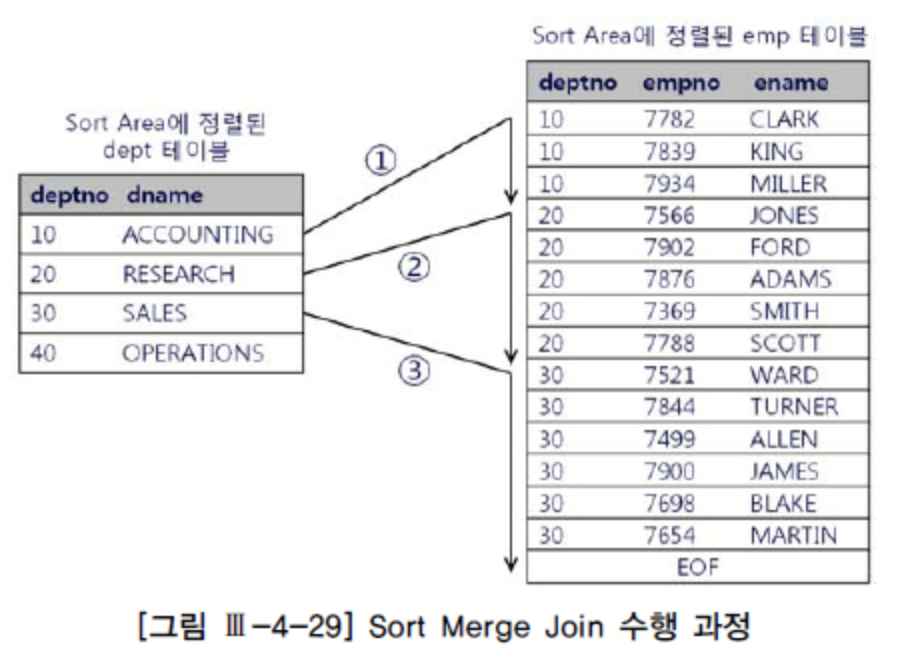
처리 과정
- 각 테이블을 조건에 따라 조회
- 결합 조건 칼럼에 따라 각 테이블 결과를 정렬 (Sort)
- 선행 테이블과 후행 테이블을 스캔하면서 병합 (Merge)
성능 상의 특징
- 결합 조건 칼럼에 Index를 추가하자.
결합 조건이 되는 칼럼에 Index가 있는 경우 정렬 과정을 생략할 수 있어 성능이 더 좋다. Index에 의해 이미 정렬되어 있기 때문이다. - 메모리 사용량이 높다.
정렬하는 과정에서 메모리를 많이 사용하기 때문에 너무 많은 데이터를 Merge Join하면 메모리 사용량이 높아져 전체 DB 성능에 영향을 줄 수 있다. 또한 메모리에서 처리하기 어려울 정도로 정렬할 데이터가 많아지면 파일에 임시 저장하기 때문에 정렬 속도도 느려진다. 이런 경우 결합 조건 칼럼에 Index를 만들면 정렬 과정을 생략할 수 있다. - Merge 횟수가 성능에 영향을 준다.
위 첨부된 이미지는 Merge가 3회지만 두 테이블 순서를 바꾸면 emp 테이블 각 row마다 Merge가 수행되므로 속도가 저하된다. 즉 조인 순서에 따라 Merge 횟수가 달라지며 Merge 횟수가 적을 수록 성능이 좋다. - 두 테이블 조회 개수가 비슷한 경우에 효율적이다.
데이터가 많은 테이블의 데이터를 조회하고 정렬하는데 오래 걸리는 경우 나머지 테이블은 그 동안 대기하고 있기 때문에 비효율적이다.
Q5. Hash Join에 대해 설명하시오. (성능 관점에서)
Hash Join
두 테이블을 조회하고 데이터가 적은 쪽 테이블의 Hash Map을 만든 후 Hash Map을 이용하여 순차적으로 결합하는 방식
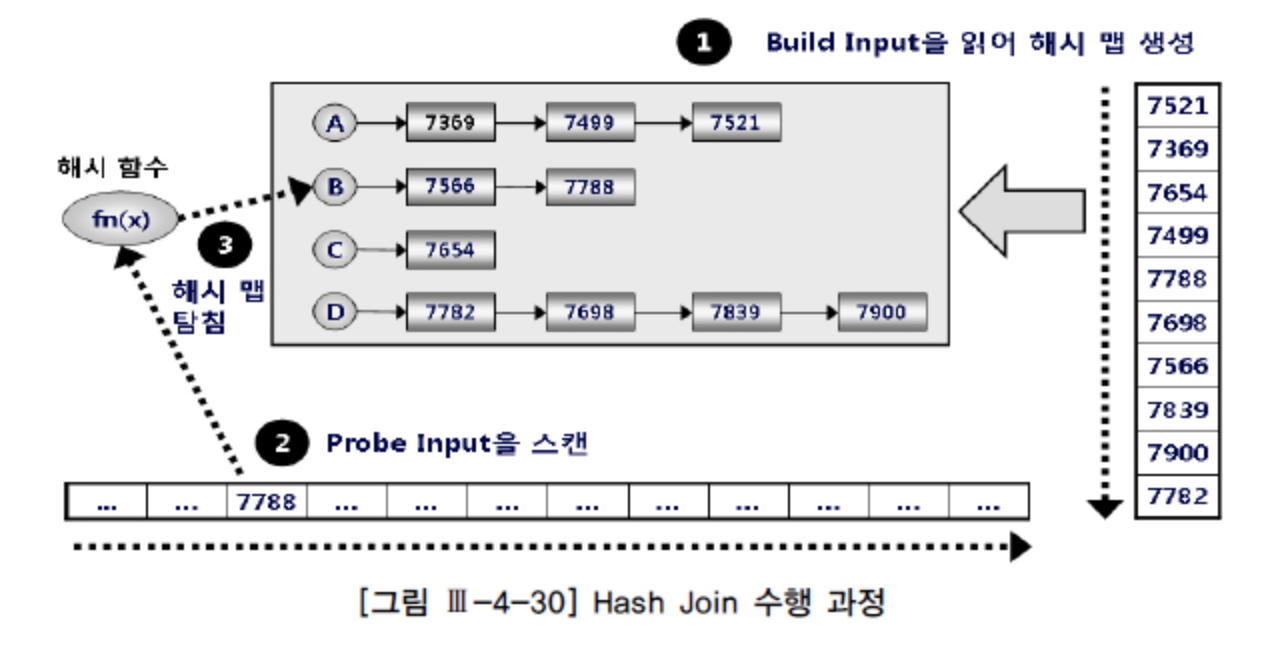
처리 과정
- 조인하려는 두 테이블 중 조회 결과(필터링)가 적은 쪽의 데이터로 해시 맵 생성
(해시 맵이 생성되는 쪽을 빌드 입력(Build Input)이라고 한다.) - 나머지 테이블 결과를 순차적으로 접근하여 해시 맵을 이용하여 결합 (Nested Loop와 비슷)
(조회의 대상이 되는 쪽을 검색 입력(Probe Input)이라고 한다.)
성능 상의 특징
- NL Join의 속도 저하를 개선
NL Join은 선행 테이블의 데이터가 많아질수록 Random Access에 의한 속도 저하가 발생한다. 이 부분을 해시 맵을 이용하여 개선하여 속도가 빠르다. 선행 데이터에서 많은 데이터를 조회하는 경우 NL Join보다 속도가 빠르다고 한다. - 해시 키에 중복이 많은 경우 비효율적
해시 맵의 충돌 해결 방법이 연결 리스트로 연결하는 방식을 사용하기 때문에 중복이 많으면 연결 리스트 스캔에 의한 오버헤드로 성능이 저하된다. - 해시 맵을 위한 메모리 공간 필요
해시 맵을 메모리에 저장하기 때문에 너무 많은 데이터를 조회하여 해시 맵이 지나치게 커지면 그에 따른 오버헤드가 발생할 수 있다. 또한 해시 맵이 커지면 파일에 임시 저장하기 때문에 해시 속도가 저하될 수 있다.
또한 매 쿼리 수행마다 해시 맵을 새로 생성하기 때문에 너무 자주 호출되는 쿼리인 경우 비효율적일 수 있다. - Equals(=) 조건에서만 사용 가능
해시를 사용하기 때문에 범위 조회가 불가능하다. 따라서 순서가 보장이 되지 않으며 순서를 사용하지 않기 때문에 Index의 여부에 상관이 없다. 정렬이 필요한 경우 조인 이후에 Order By절로 정렬을 해야 한다.
정리) 각 Join을 선택하는 포인트 정리
Nested Look Join
- 대부분의 경우는 이 조인 방식을 사용
- 성능이 느리다면 선행 테이블의 데이터가 많은지 확인 (불필요한 조회 제거)
- 실행 계획을 확인하고 인덱스 및 쿼리 튜닝
Merge Join
- NL Join을 사용했을 때 Random Access에 의해 성능이 느릴때 사용 고려
- 두 테이블의 크기가 비슷한 경우에 효과적
- 결합 조건 칼럼에 Index가 있는 경우 효과적(정렬 과정 생략)
- Merge 횟수가 적을 수록 효과적
Hash Join
- NL Join이 Random Access로 성능이 느릴때 혹은 적당한 인덱스가 없어 NL Join이 비효율 적일때 고려
- Merge Join을 하기에 테이블이 커서 정렬이 느린 경우 고려
- 쿼리의 수행 빈도가 적은 경우 효과적 (매번 해시 맵을 생성해야 하므로)
- 해시 맵이 메모리에서 충분히 생성될 수 있는 경우 효과적
- Build Input에 중복 키가 거의 없는 경우 효과적